기존의 잔차 연결은 수많은 '더하기(+)' 연산을 거치며 정보가 뭉개지는 한계
https://arxiv.org/html/2603.15619v1
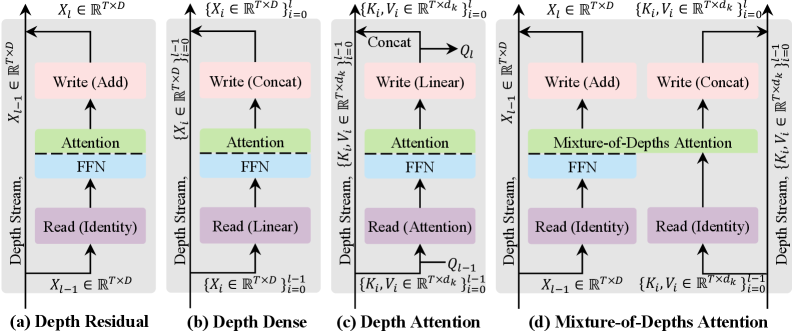
Mixture-of-Depths Attention
We study whether the gains of MoDA persist when scaling model size from 700M to 1.5B under the same training budget of 400B tokens. We report downstream benchmark results in Table 4 and domain-level validation perplexity in Table 5. From these two tables,
arxiv.org
쓰기
각 층이 계산을 끝낼 때마다, 자신의 K, V 값을 Depth Stream 이라는 전용 저장소에 차곡차곡 쌓음(append) : 요약 본 아님.
(현재 내가 이해한게 맞다면 가중치가 적용된 원본을 의미할 것)
읽기
다음 층의 어텐션 헤드는 현재 층의 데이터 뿐만 아니라, 이 Depth Stream 전체를 검색 대상에 포함
데이터 의존적 선택
어텐션 메커님즘이 일종의 포인터 역할을 하여, 수많은 과거 데이터 중 현재 토큰과 가장 유사도가 높은(중요도) 과거 층의 데이터를 선택

KIMI AttnRes(Attention Residual Connection)과 비교해 보기

이론
| MoDA(어텐션 확장) | AttnRes(잔차 연결 대체) | |
| 작동 위치 | 어텐션 레이어 배누 | 레이어와 레이어 사이 전차 연결 |
| 핵심 원리 | 현재 층에서 단어 간의 관계를 계산할 때, 현재 층의 정부뿐만 아니라 이전 층들이 만들어둔 기록 보관소(KV cache)를 직접 열어보고 함께 계산 | 기존에 이전 층의 결과물을 무조건 1:1 단순 덧셈 처리. AttnRes는 이 덧셈 자리에 어텐션을 배치. 즉 과거 모든 층의 출력물들을 쳐다보고 몇 번째 측의 정보가 지금 가장 필요한가?를 가중치로 계산하여 비율적 처리 |
장점
| MoDA(어텐션 확장) | AttnRes(잔차 연결 대체) | |
| 장점1 : 정보 복원력 | 직접적인 특징 복구 - 얕은 층의 정보가 희석되었을 때 직접 과거 KV를 당겨와 복구함 |
은닉 상태 크기 제어 - PreNorm 구조에서 출력이 무제한으로 커지는 수학적 결함을 직접 해결 |
| 장점2 : 연산 효율 | 극도로 낮은 연상 오버헤드 - 맞춤형 CUDA 커널 설계로 연상 증가량이 3.75에 불과 |
학습 안정성 확보 - 매우 깊은 모델에서도 그레이언트 분상이 안정적임 |
| 장점3 : 구현 최적화 | KV 재사용성 기존 추론 시 생성되는 KV 풀을 활용하기 용이함 |
구조적 스케일링 - 레이어를 블록 단위로 묶어 연산 복잡도를 물리적으로 낮출 수 있음 |
단점
| MoDA(어텐션 확장) | AttnRes(잔차 연결 대체) | |
| 정규화 제약 - PreNorm보다 PostNorm 결합 시 우수하여 학습 초기 안정화 난이도가 높음 |
은닉 상태 크기 제어 - 더셈만 하던 전차 연결에 어텐션이 들어가 통신량 및 대역폭 요구 증가 |
|
| 하드웨어 종속성 - 효율을 내기 위해 비연속 메모리 접근을 해결하는 맞춤 커널이 필수적임 |
추론 캐시 증가 - 블록화하더라도 과거 층의 합축 표상(Representation) 캐시를 유지해야 함 |
|
| 초장기 문맥 한계 - 시퀀스가 너무 길어지면(e.g. 128K 이상) 참조할 과거 KV가 너무 많아짐 |
아키텍처 파편화 - 기존 트랜스포퍼의 표준적이고 단순한 덧셈 구조를 완전히 해체해야 함 |
MoDA
잔차 연결 때문에 정보가 희석되니, 아예 옆에 전용 직통 차선을 하나 더 깔아 과거의 원본 데이터를 직접 가져오기
AttnRes
그냥 무식하게 더하기만 하는 잔차 연결을 비효율적이기 때문에 스파트한 필터를 달아서 과거 데이터 중 중용한 것만 골라서 섞자
잔차
- 통계학에서 전차는 모델이 예측한 값과 실체 값의 차이를 뜻함(정밀도)
- 인공지능 잔차는 입력값과 출력값의 차이. 다음 층으로 넘겨줄 데이터와 현재 데이터 사이의 남은 차이만 계산. 즉 원본 데이터를 다음 층에 보내려는 과정
[ AI/KIMI ] Beyond Standard Residuals
이제 엔진을 더 갈고 닦아보자. 기술의 발달함에 있어서 기능을 더 갈고 닦는 것이 시대의 흐름이다.이번 KIM가 기존 LLMs의 모델의 한계를 확인하고 그걸 개선한 논문이다.다만, 개인적인 생각은
life-explorer.tistory.com
한계
모든 층이 자신의 원본 KV를 계속 '스트림'에 누적해서 저장해야 하므로, 모델이 깊어질수록 메모리(VRAM) 사용량이 기하급수적으로 폭발(이를 Depth-wise KV Cache라고 부릅니다).
연산량(FLOPs)은 적게 늘어난다고 논문은 주장하지만, 실제 하드웨어에 배포할 때는 메모리 대역폭(Bandwidth) 병목 현상으로 인해 추론 속도가 급격히 느려질 수 있음.
'AI' 카테고리의 다른 글
| [ AI/Claude ] Anthropic에서 제공하는 수업듣기-3(Feat. Claude 101) (0) | 2026.03.24 |
|---|---|
| [ AI/Claude ] Anthropic에서 제공하는 수업듣기-2(Feat. Claude 101) (0) | 2026.03.23 |
| [ AI/KIMI ] Beyond Standard Residuals (0) | 2026.03.19 |
| [ AI/Claude ] Anthropic에서 제공하는 수업듣기-1(Feat. Claude 101) (0) | 2026.03.17 |
| [ AI/Vision ] 언어와 시각을 한 번에 처리하는 게 어쩌면(Feat. world model) (0) | 2026.03.17 |



