멀티모달, 통합 데이터 처리
인간이 가장 먼저 멀티모달을 느끼는 시점은 아이가 엄마의 행동과 말을 보면서 일 것이다.
엄마는 하는 말과 행동에서 동일한 행동이지만 다른 모달리티의 차이를 느끼기 때문이다.
이미 Frontier 집단은 세상 밖으로 나오고 있다.
이유는 뭐 인터넷 데이터의 한계이지 않을까?
Beyond Language Modeling: An Exploration of Multimodal Pretraining
Unified models (Zhang et al., 2025a; Xiao et al., 2025; Geng et al., 2025; Xu et al., 2025a; Xin et al., 2025; Li et al., 2025a; Wang et al., 2025b; Wei et al., 2025; Wang et al., 2025a; Li et al., 2025d; Nguyen et al., 2025; Pan et al., 2025; Li et al., 2
arxiv.org
멀티모달 AI 4가지 특징
시각 표현(RAE) :
시각 정보를 이해하는 눈과 생성하는 손을 동시에 갖춘 통합적 능력 발현
RAE(Representation Autoencoder)란 시각 데이터를 AI용 암호로 압축하고 다시 그림으로 복원하는기술로, 이해와 생성 모두에서 압축적인 성능을 보임
데이터 시너지:
시각과 언어 데이터가 만나면 서로를 보완하여 개별 학습 시보다 성능이 향상
글로만 배울 때보다 영상을 함께 볼 때 더 깊이 이해할 수 있다는 원리
월드 모델링:
다양한 데이터를 접한 AI는 세상이 돌아가는 물리적 법칙을 스스로 시뮬레이션하기 시작
인위적인 주입 없이도 일반적인 학습 과정 중에 서셍을 이해하는 지능이 시작
효율적 구조:
서로 성격이 다른 시각과 언어를 전문가 집단이 나누어 처리하여 효율성 극대화
MoE는 모든 문제를 한 명이 푸는 게 아니라 여러 전문가가 자기가 잘하는 전문 분야 담당
Transfusion 프레임워크
Transfusion 프레임워크 내에서 MoE(Mixture-of-Experts) 아키텍처가 결합해 언어는 '예측'으로, 시각은 '확산'으로 처리하는 이원화된 전략을 취하면서도, MoE를 통해 자원 배분을 최적화
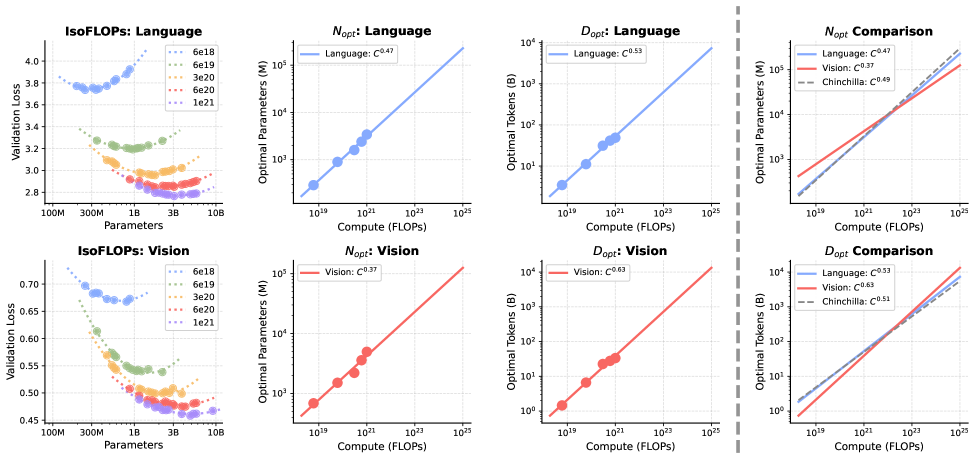
어떻게 데이터 비대칭을 처리하는 가?
'확장 비대칭'의 본질: 머리(용량) vs 공부량(데이터)
언어 (Language):
똑똑해지려면 아주 큰 '두뇌(모델 용량)'가 필요
파라미터 수가 많아야 복잡한 논리와 지식을 담을 수 있음
시각 (Vision):
똑똑해지려면 엄청나게 많은 '문제집(데이터량)'을 풀어봐야 함
언어보다 훨씬 더 방대한 데이터를 처리해야 패턴을 익힘

한계
1. 처음부터 학습하는 방식을 취했기 때문에 비용 이슈 및 대규모 상용 모델에서의 적용 양상은 조금 다를 수 있을 것
ps-
여긴 또 다른 용어로 이해하긴 쉽진않네요
'AI' 카테고리의 다른 글
| [ AI/KIMI ] Beyond Standard Residuals (0) | 2026.03.19 |
|---|---|
| [ AI/Claude ] Anthropic에서 제공하는 수업듣기-1(Feat. Claude 101) (0) | 2026.03.17 |
| [ AI/LLMs ] 어쩌면 훈련의 방식이 조금 저렴해질지도(Feat. Fine-tunring) (1) | 2026.03.15 |
| [ AI/LLMs ] scaling law의 한계(Feat.FineWeb datasets) (0) | 2026.03.14 |
| [ AI/Harness ]하니스란 말은 무엇인가? (feat. LLMs 외 전부) (0) | 2026.03.08 |



