앞에서 Pre-training에 대해서 간략하게 알아 봤다.
이제 사람처럼 말하는 말투와 더 완전한(?) 결과를 내기 위한 작업을 수행한다.
Post-training은 실생활에 실용성을 높이는 작업
Post-training은 무엇일까?
개인적인 생각으로는 사람 최적화이다.
카카오 tech blog
Pre-training 단계에서는 다음 단어를 예측하는 방식으로 다양한 “문서”들에 대해서 학습하기 때문에 사용자가 제시하는 명령을 “이해하고 수행”하는 데 필요한 능력은 부족한 경우가 많습니다. 따라서 모델이 사용자의 명령을 인식하고 적절히 반응할 수 있는 LLM을 만들기 위해서는 적절한 Post-training 과정을 거쳐야 합니다.
https://tech.kakao.com/posts/662
LLM Post-Training: A Deep Dive into Reasoning Large Language Models
Pretraining on vast web-scale data has laid the foundation for these models, yet the research community is now increasingly shifting focus toward post-training techniques to achieve further breakthroughs. While pretraining provides a broad linguistic foundation, post-training methods enable LLMs to refine their knowledge, improve reasoning, enhance factual accuracy, and align more effectively with user intents and ethical considerations.
https://arxiv.org/html/2502.21321v1
두가지 이야기를 종합해보면,
청소년기의 아이를 조금 더 성인과 같이 정리정돈된 생각을 만드는 과정.
이렇게 표현해보고 싶다.
제가 생각하는 주요학습으로는 Post-training의 특징은
- 특정 도메인에 대한 전문 지식 습득
- 사용자의 지시를 정확하게 이해하고 따르는 능력 향상
- 인간의 가치관과 선호도에 부합하는 응답 생성
- 복잡한 추론 능력 및 문제 해결 능력 강화
- 환각(Hallucination)과 같은 부적절한 답변 생성 감소
Fine-runing
사전 학습된 모델의 모든 또는 일부 파라미터를 특정 작업이다.
비교적 작은 규모의 데이터셋으로 추가 학습시키는 방법이다.
하여 특정 분야나 작업에 LLM을 특화시켜 성능을 극대화 한다.
법률 문서 Fine-tuning: 법률 관련 질의응답, 계약서 분석 등에 특화된 모델 제작.
고객 상담 데이터 Fine-tuning: 고객 문의에 대한 빠르고 정확한 답변을 제공하는 챗봇 개발에 활용.
RLHF(Reinforcement Learning from Human Feedback )

2021년 부터 많은 아르바이트 중에 라벨링 아르바이트가 생겼는데,
아마도 이 과정이라고 생각한다.
인간 평가자의 피드백을 활용하여 LLM이 인간의 선호도 학습이다.
이유는 LLM의 답변 품질, 안전성, 유용성 등을 향상시킨다.
나아가 인간의 가치관에 더 잘 부합하도록 조정한다.
사실 여기선 대중적으로 작업을 하는 사람도 있지만,
전문가들이 들어가서 적절한 학습을 시키는 경우도 상당하다.
어떻게 학습하는가?
인간의 취향을 따라하게 만드는 것이다.
질문의 100개를 만들고 거기서 5개의 선택지를 출력한다.
거기서 인간이 5개에 질문의 선호를 점수가 아닌 순서를 부여한다.
이렇게 모든 질문에 순서를 정하면 LLM 모델은 보상모델로 인하여
조금씩 조절된다.
환각(Hallucination)
LLM 환각은 뭘까?
In the field of artificial intelligence (AI), a hallucination or artificial hallucination (also called bullshitting, confabulation or delusion) is a response generated by AI that contains false or misleading information presented as fact.
https://en.wikipedia.org/wiki/Hallucination_(artificial_intelligence)
다시 말해, 잘못된 혹은 실패한 정보를 계속 생성해서 알려주는 것을 말한다.
그렇다면 왜 그럴까?
LLM은 인터넷에 있는 특정 시점까지의 정보를 압축해 놓은 백과사전같은 것이다.
여기서 정보를 찾아서 출력은 통계를 기반으로 한다.
이걸 다른 말로 neural network 기반이라고 한다.
즉, 환각은 자신이 알고 있지 못하는 정보를 계속 출력하는 현상인 것이다.
하여 이런 부분을 보완하게 위해서 최근 GPT는 '검색'이라는 버튼이 만들어진 것이다.
LLM 데이터 + 인터넷 검색을 통해서 정보를 모으고 추출해서 추가적인 정보를 제공한다.
"확률"과 "생성"이 키워드다.
내가 질문한 것에 대한 답변에 정확도 확률이 낮아지는 것 뿐이다.
계속해서 생성은 이뤄지는 것이다.
초기 Pre-training 과정을 살펴보면, token 기준으로 답변을 한다.
만약 token 제한 개수가 완료되면 도중에 말을 멈춰버리는 현상을 볼 수 있다.
그래서? RLHF
인간 평가자는 모델이 생성한 답변의 사실 여부를 판단한다.
Hallucination이 포함된 답변에 대해 부정적인 피드백을 제공한다.
하여 Post-Training 과정에서 모델이 불확실한 정보에 대해 "모르겠다"라고 유도한다.
RLHF를 통해 이러한 행동을 장려할 수 있다.
번외) Strawberry에서 "r" 은 몇개?

LLM은 사실 셈과 계산에 약하다.
그중에서 샘에 약한다. 위의 사례를 보면 알 수 있다.
Strawberry(딸기)라는 영어 단어에서 r은 총 몇개인가?
총 3개이지만 지금(2025.03 기준) 2개라고 말한다.
현재 GPT는 업데이트되서 정확하게 센다(아마도 강제로 하드코딩 했다는 이야기가 있다.)
이유는 다음과 같이 생각한다.
strawberry를 텍스트고 LLM은 텍스트로 token으로 만든다.
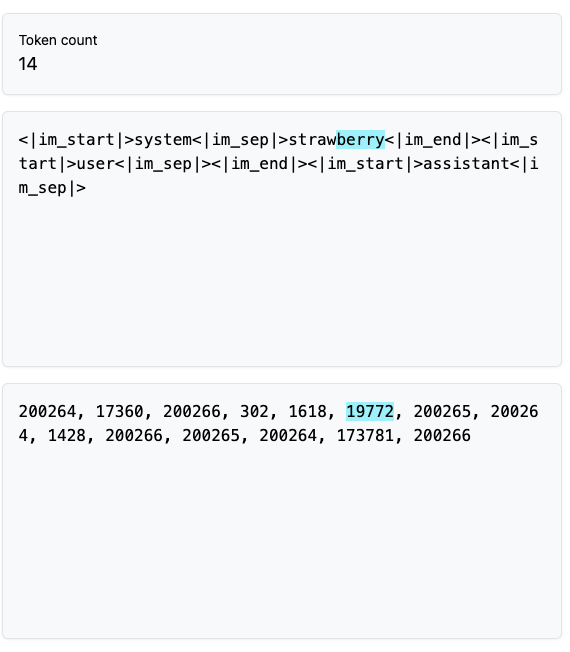
berry 부분은 19772로 tokenization되서 셈을 할 수 없는 것이다.
요약
Post-training은 사람들에게 실생활에서 사용하기 위한 작업이다.
그리고 여전히 LLM은 한계가 있다.
많은 LLM 회사들은 환각과 같은 한계를 극복하기 위해서 고민중인 거 같다.
앞에서 언급한 것처럼 Open AI의 '검색' 버튼 처럼 말이다.
ps-
여기서 작성된 글은 다양한 정보를 짜집기 한 것임을 밝힌다.
'AI' 카테고리의 다른 글
| [ LLMs ] 나는 누구인가? 곧 자기에 장점이 나다.(feat. Grok, Chat GPT, Claude, Perplexity, Gemini) (1) | 2025.04.06 |
|---|---|
| [ AI/애착 ] 우리는 AI와 친구가 될 수 있을까? (Feat.Open AI) (0) | 2025.03.23 |
| [ AI/LLM ] PRE-TRAINING을 간단히 알아보자 (3) | 2025.03.12 |
| [ AI /Chat ] Chat GPT의 다양한 기능을 사용해 보자 (0) | 2025.03.10 |
| [ AI / AWS ] 아마존 AWS 제공하는 재미있는 서비스 (Feat.PartyRock) (0) | 2024.11.19 |



