LLM은 기본적으로 2가지 방식으로 구성된다.
PRE-TRANING 그리고 POST-TRAINING.
먼저 PRE-TRANINING에 대해서 이해해보자.
요약하면 빅데이터를 활요해 확률에 기반 언어 예측률 높이는 것이 PRE-TRAINING이다.
순서
1. 데이터 수집 및 전처리 (Data Collection and Preprocessing)
2. 토큰화 (Tokenization)
3. 신경망 학습 (Neural Network Training)
4-1. 추론 (Inference)
4-2. 결과물 : 베이스 모델 추론 (Base Model Inference)
1. 데이터 수집 및 전처리
보통은 데이터 수집은 이미 된 정보를 가지고 다음에 진행을 한다.
간단히 말해서 인터넷에 돌아다니는 "텍스트" 정보를 스크롤해 정보를 축적하는 것이다.
웹 페이지는 마크다운 언어로 되어 있다.
여기서 필요한 건 Text값이다. <ul> <li> 이런 태그 값이 아니다.
이 과정에서 "필더링"을 통해 정보 신뢰도를 높인다.
인터넷은 정보의 바다이다. 그만큼 정보다 많지만 잘못된 정보도 많다.
다시 말해, 비정제된 정보를 인터넷에서 추출해서 압축해서 거대한 정보값으로 만든다.
그때, 토큰이 필요하다.
2. 토큰화(Tokenization)
토큰은 간단히 말해서 위에 추출한 "텍스트"정보를 8bit로 바꾸고 그걸 다시1byte로 바꾼다.

그러면 우리의 Chat LLM은 아래처럼 우리의 텍스트를 인식한다.
(오른 상단을 보면 Token count : 16을 확인할 수 있다.)

텍스트 바이트 페어 인코딩을 통해 토큰이라는 심볼로 변환 한다.
토큰화를 하는 이유는 다음과 같다.
1. 기계는 텍스트 정보를 이해할 수 없다.
2. 각 토큰은 고유한 ID에 매핑되고 모델이 이를 ID를 사용하여 텍스트 숫자 시퀀드로 처리 한다.
3. Subword 토큰화(eg. Byte Pair Endcoding, WordPiece)를 사용하면
자주 등장하는 단어 조합이나 형태소를 토큰으로 처리하여 어휘 크기를 효율적을 관리 가능하다.
4. 텍스트는 어휘 크기가 너무 커 비용이 많이 든다.
3. 신경망 학습(Neural Network Training)
신경망 학습 초기에는 입력된 토큰 시퀀스를 바탕으로 다음 토큰을 예측하는데 사람의 말이 아니다.
따라서, 학습을 계속 시키면 점점 사람이 하는 말의 형태와 유사한 패턴으로 텍스틑 생성해 낸다.

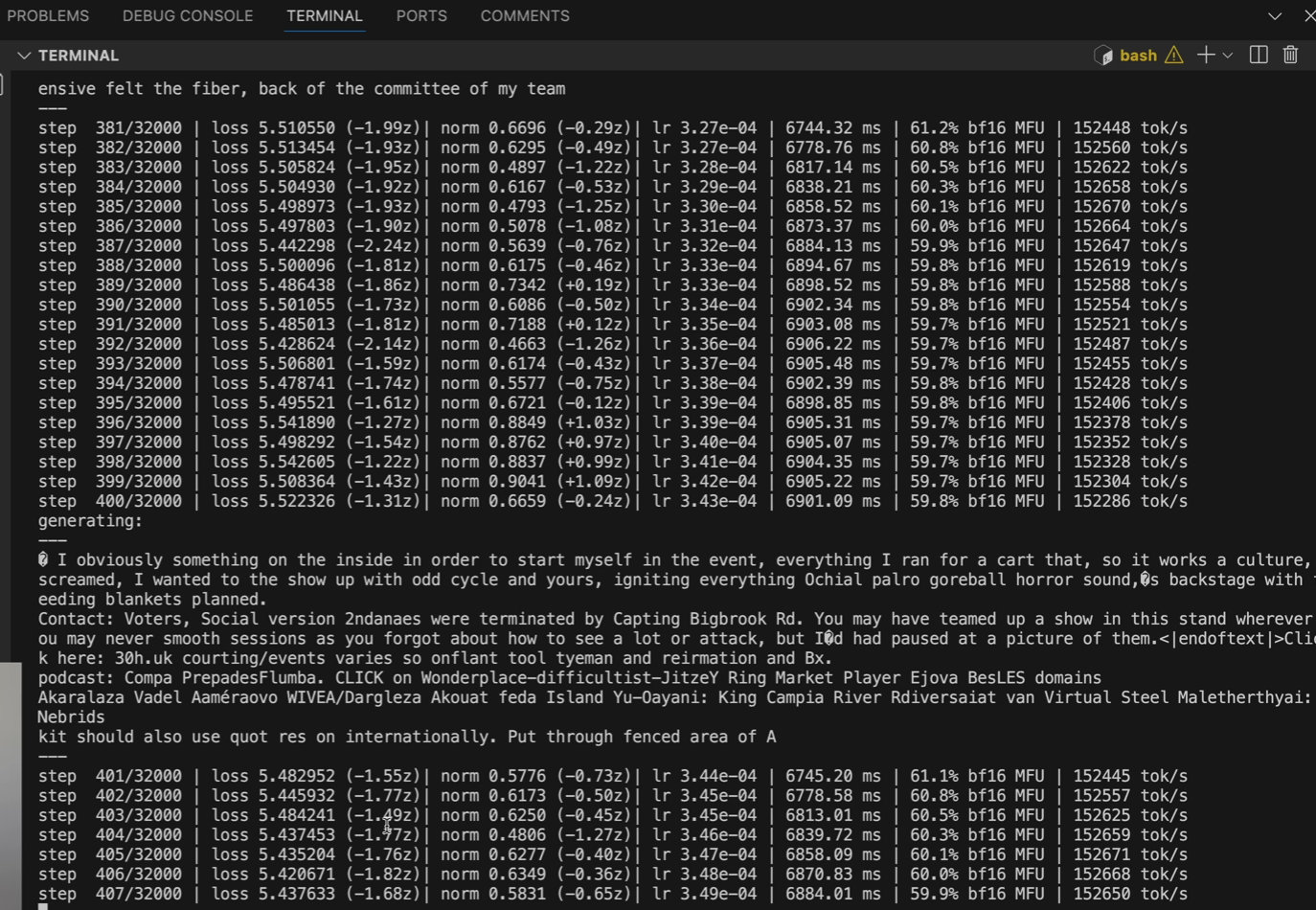
신경망 내부엔 파라미터(위의 사진, 왼쪽)를 반복적으로 조정하여 학습데이터 패턴을 따른다.
neural network training을 시키는 과정은 LOG 정보 값들(위의 사진, 오른쪽)이다.
여기서 파라미터 조정(가중치 조정)이 일어난다.
파라미터를 조정하면 다음 예측 단어가 조금씩 달라진다.
즉 더 정교하게 인간의 언어와 유사해진다는 표현이 아직은 맞을 것이다.
이러한 위의 과정을 빠르고 성능 좋은 GPU를 사용해서 더 많은 시간을 학습시키는 것이다.
그래서 NVDA의 주식이 그렇게 하늘 높은 줄 모르고 오르는 것이다.
4. 추론(Inference) / Base Model Inference
위의 과정을 여러번 걸쳐 학습된 모델을 사용하여 새로운 데이터를 생성한다.
주요 특징
어시스턴트가 아님: 단순한 토큰 자동 완성 기능이다.
확률적: 동일한 질문인데, 예측이 매번 달라질 수 있다.
베이스 모델 자체는 유용성이 제한적이지만,
다음 토큰 예측 작업에서 세상에 대한 지식을 학습하고 네트워크 파라미터에 저장한다.
여기서 몇가지 알아두면 좋은 사실은
epochs: 위키피디아와 같은 중요 페이지를 10회 정도 학습 시킨다.
환각(hallucination): 모델이 최선을 다해 추측하지만, 최신 정보가 아닐 경우 잘못된 정보를 생성할 수 있다.
In-context learning: 프롬프트 내에서 패턴을 학습하는 능력있다.
이러한 과정을 거치면서 LLM의 PRE-TRAININING이 완료된다.
이과정이 LLM을 만들기 위한 여러 단계중 하나이다.
따라서, LLM을 확률 예측모델이라고 하는 것이다.
그걸 비용과 빅이익~ 데이터로 커버리해린 것일 뿐.
ps-
공부하는 내용이다보니, 정리한 정보가 부정확할 수 있다.
'AI' 카테고리의 다른 글
| [ AI/애착 ] 우리는 AI와 친구가 될 수 있을까? (Feat.Open AI) (0) | 2025.03.23 |
|---|---|
| [ AI/LLM ]Post-training에 대해서 (4) | 2025.03.20 |
| [ AI /Chat ] Chat GPT의 다양한 기능을 사용해 보자 (0) | 2025.03.10 |
| [ AI / AWS ] 아마존 AWS 제공하는 재미있는 서비스 (Feat.PartyRock) (0) | 2024.11.19 |
| [ Article / AI ] AI는 어떻게 우리의 질문에 답할까? (0) | 2024.10.12 |



