모델 훈련의 방식의 변화
https://arxiv.org/html/2603.12228v1
Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights
“[Random guessing] cannot be viewed as a reasonable learning algorithm…” — Schmidhuber, Hochreiter, Bengio, 2001
arxiv.org
아래 이미지는 데이터의 결과 값이니 참조용으로 아래 해석과 함께 볼 것
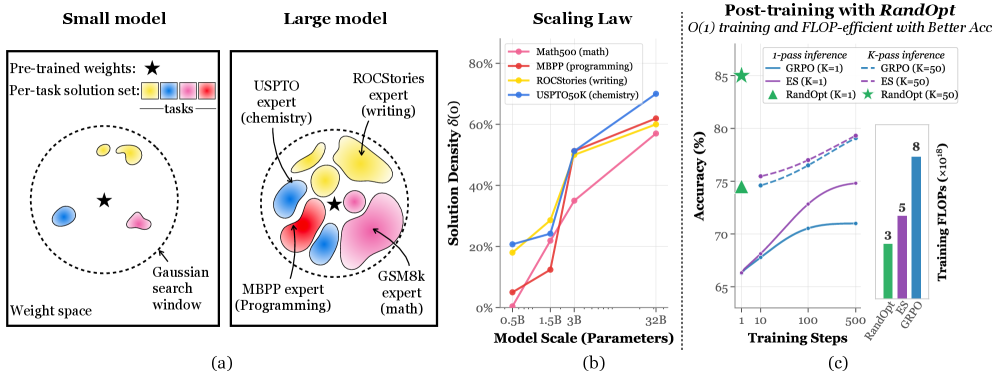
(a) 가중치 공간의 시각화 (Small vs Large Model)
이 그림은 모델 크기에 따라 '정답 가중치'가 어디에 위치하는지
- Small model (왼쪽): 사전 학습된 지점(별표) 주위에 정답 영역(색칠된 구역)이 매우 작고 멀리 떨어져 있습니다. 점선으로 된 '검색 범위' 안에 정답이 거의 없기 때문에, 경사 하강법과 같은 정밀한 최적화 도구를 써서 정답을 향해 가중치를 길게 이동시켜야만 합니다. 이를 '모래사장에서 바늘 찾기(Needle in a haystack)' 상황으로 정의합니다.
- Large model (오른쪽): 모델이 커지면 사전 학습된 지점 주변에 화학(USPTO), 프로그래밍(MBPP), 글쓰기(ROCStories), 수학(GSM8k) 등 다양한 분야의 전문가 가중치가 '덤불(Thicket)'처럼 빽빽하게 들어차 있습니다. 굳이 멀리 이동할 필요 없이, 주변을 조금만 뒤져도(Random Sampling) 바로 전문가를 찾을 수 있는 상태가 됩니다.
(b) 척도 법칙 그래프 (Scaling Law)
이 그래프는 모델이 커질수록 전문가 가중치를 발견할 확률이 얼마나 높아지는지를 데이터로 입증
- X축 (Model Scale): 모델의 파라미터 크기(0.5B에서 32B까지)를 나타냅니다.
- Y축 (Solution Density): 사전 학습된 가중치 주변에서 특정 작업을 개선하는 가중치가 발견될 확률(밀도)을 의미합니다.
- 해석: 0.5B(5억 개) 규모에서는 밀도가 0%에 가깝지만, 32B(320억 개) 규모로 넘어가면 모든 작업(수학, 프로그래밍, 화학 등)에서 밀도가 60~70% 이상으로 급격히 상승합니다. 즉, 모델이 커질수록 무작위로 가중치를 조금만 수정해도 성능이 좋아질 확률이 비약적으로 높아진다는 증거입니다.
(c) RandOpt의 효율성 및 성능 비교
이 그래프는 저자들이 제안한 새로운 방법론인 RandOpt가 기존의 복잡한 학습 방식과 비교해 얼마나 효율적인지 보여줍니다.
- 왼쪽 그래프 (Accuracy vs Training Steps): * 기존 방식인 GRPO나 ES는 성능을 올리기 위해 수백 단계(Steps)의 반복 학습이 필요합니다.
- 반면, **RandOpt(초록색 세모/별)**는 학습 단계가 거의 0인 상태(1-pass)에서도 수백 단계를 학습한 기존 모델들과 대등하거나 더 높은 정확도를 보여줍니다.
- 특히 $K=50$ (50개의 무작위 모델을 투표시킴) 방식은 최고 수준의 성능을 즉각적으로 냅니다.
- 오른쪽 막대 그래프 (Training FLOPs): * 학습에 들어가는 총 연산량(비용)을 비교한 것입니다.
- RandOpt는 기존 GRPO 방식에 비해 **약 37% 수준의 연산 비용(3 vs 8)**만 사용하면서도 동일한 효과를 냅니다. 이는 사후 학습(Post-training) 비용을 획기적으로 낮출 수 있음을 의미합니다.
RandOpt : Randomized Optimization(무작위 최적화)
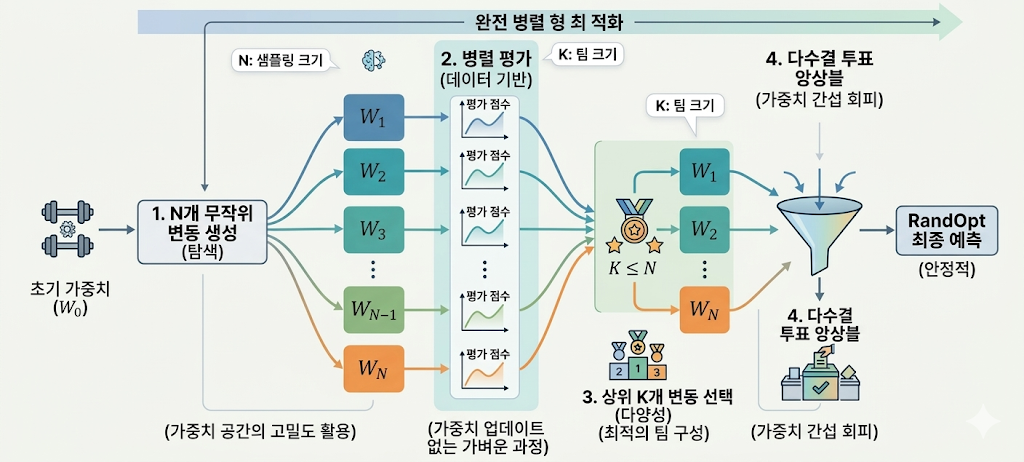
RandOpt는 $N$개의 모델을 동시에 만들고 평가할 수 있어 계산 효율성이 극도로 높힘
1. 아무거나 찔러도 전문가가 나올 확률이 높다(Thicket)"는 전제가 있기에, 복잡한 최적화 없이 단순한 무작위 변동만으로 후보군을 생성
2. 앙상블을 활용한하여 한 명의 천재를 찾는 대신, 각기 다른 장점을 가진 $K$명의 전문가를 모아 팀을 구성하는 전략
3. N이 커질수록 더 뛰어난 전문가를 발견할 확률이 높아짐. + 평가 수행, 이 과정이 가중치를 직접 업데이트하는 '학습'보다 훨씬 가벼움
4. 최종 상위 전문가 수(너무 적으면 다양성이 부족하고, 너무 많으면 성능이 낮은 모델이 섞일 수 있는 최적화 지점이 존재)
5. 다수결 투표를 통해 각 모델이 내놓은 '답변)'들을 모아 가장 많이 나온 답을 선택. 여기서 가중치 공간에서의 간섭 문제를 피함
가중치 공간에서 간섭이란?
하나의 모델 안에 수학을 잘하게 만드는 가중치와 글쓰기를 잘하게 만드는 가중치가 억지로 섞으려다가 충돌하는 상황.
하여. 다수결 투표를 통해서 두 모델을 따로 분리하고 독립적으로 답변을 생성한 뒤 나온 정답을 채택
장점 (학습 관점에서는 압도적 이득)
- 학습 비용(Training FLOPs)의 극단적 감소: 모델의 가중치를 미분하고 역전파(Backpropagation)하는 복잡한 계산이 아예 사라집니다. 단순히 모델을 $N$개 복사해서 테스트만 해보면 되므로 학습에 드는 전기와 연산 자원이 기존 대비 30~40% 수준으로 줄어듭니다.
- 파괴적 망각 완벽 차단: 모델을 합치지 않기 때문에, 코딩 능력을 올리려다 언어 이해력이 떨어지는 등의 부작용을 원천적으로 막을 수 있습니다.
- 병렬 처리의 극대화: $N$개의 모델을 평가하는 과정은 서로 아무런 연관이 없으므로, GPU가 많다면 한 번에(Fully Parallel) 던져서 순식간에 학습(평가)을 끝낼 수 있습니다.
- 특화(Specialization) 역량 보존: 각 모델이 가진 뾰족한 재능을 죽이지 않고, 가장 필요한 순간에 꺼내 쓸 수 있는 강력한 전문가 팀을 꾸릴 수 있습니다.
단점 (실사용/추론 관점에서는 막대한 비용)
- 추론 에너지 및 토큰 소모량 $K$배 증가: 이 부분이 가장 큰 단점입니다. 사용자가 질문을 하나 던졌을 때, 시스템 뒤에서는 $K$개(예: 50개)의 모델이 동시에 똑같은 질문을 읽고 각자 답을 생성해야 합니다. 즉, 내부적으로 소모되는 토큰과 전기 에너지가 단일 모델 대비 50배 늘어납니다.
- 응답 지연 시간(Latency)의 증가: 다수결 투표를 하려면 $K$개의 모델이 모두 대답을 끝낼 때까지 기다렸다가 답을 취합해야 합니다. 막대한 인프라가 갖춰져 있지 않다면 사용자는 답변을 받기까지 훨씬 더 오랜 시간을 기다려야 합니다.
- 거대한 VRAM(메모리) 요구량: 서로 다른 가중치를 가진 $K$개의 거대 모델을 메모리에 올려두고 서빙해야 하므로, 서버 유지비가 기하급수적으로 상승합니다.
- 평가 데이터의 중요성: RandOpt의 성능은 상위 $K$개를 골라내는 '평가 기준'에 전적으로 의존합니다. 만약 평가 데이터(Reward Model 등)에 편향이 있다면 무작위로 뽑힌 모델들도 그 편향을 따라갈 위험이 있습니다.
이 연구의 목적와 의의
신경 씨킷(Neural Thickets)의 증명:
사전 학습된 대형 모델의 가중치 주변에는 이미 수많은 '전문가 가중치'들이 널려 있다는 사실을 증명하는 탐침(Probe) 역할로 이 알고리즘을 사용한 것
결국 복잡한 강화학습 없이 '운 좋게 근처에서 잘하는 놈들을 골라내는 것'만으로도 성능이 올라간다는 점을 보여줌으로써, 사전 학습의 강력함을 재조명
결론적으로, 추론 비용이 늘어나는 것은 맞지만 이를 증류를 통해 해결할 수 있으며, 무엇보다 훈련 시간을 극단적으로 단축할 수 있다는 점
RandOpt의 증류(Distillation) 과정은 앙상블 모델(개)의 높은 성능은 유지하면서,
추론 시 발생하는 배의 연산 비용을 단일 모델() 수준으로 낮추기 위해 설계
증류의 한계
한계: 현재의 증류 방식은 주로 수학적 추론처럼 최종 정답이 명확한 카테고리형 예측에 최적화되어 있으며, 스토리텔링과 같은 구조적 예측에는 적용이 더 까다로울 수 있음
ps-
개인적으로 pretraining까지 하면 데이터 군집이 생긴다는 것과 이것을 활용해서 뭔가 더 해볼 수 있지 않을까하는 상상아닌 생각이 감
모델 데이터 훈련 파이프라인
1. Data Collection & Curation (데이터 수집·정제)
2. Pretraining (사전 학습)
3. Supervised Fine-Tuning (SFT)
4. Preference Learning (RLHF 등)
5. Post-Training / Alignment / Safety
Pretraining
↓
Fine-Tuning
├─ Instruction / SFT
├─ Preference Learning (RLHF / DPO)
└─ Safety Alignment
'AI' 카테고리의 다른 글
| [ AI/Claude ] Anthropic에서 제공하는 수업듣기-1(Feat. Claude 101) (0) | 2026.03.17 |
|---|---|
| [ AI/Vision ] 언어와 시각을 한 번에 처리하는 게 어쩌면(Feat. world model) (0) | 2026.03.17 |
| [ AI/LLMs ] scaling law의 한계(Feat.FineWeb datasets) (0) | 2026.03.14 |
| [ AI/Harness ]하니스란 말은 무엇인가? (feat. LLMs 외 전부) (0) | 2026.03.08 |
| [ AI/Claude ]Dario Amodei 인도에서 그래도 비전을 말해보다 (1) | 2026.03.03 |



