HRM 2개의 층을 갖고 뇌와 유사한 모델의 새로운 길
사람도 똑같다. 몇번의 문제를 동일하게 읽고 풀면 달라보일 때가 있다.
특히 책을 읽을 때 많이 느낀다.
'이 책에 이런 문장이 있었다고?'
재귀적 추론(Recursive Reasoning) 동일한 문제에 계속적으로 반복 수행함으로써 높은 성과를 높인다.
Less is More: Recursive Reasoning with Tiny Networks
Less is More: Recursive Reasoning with Tiny Networks Abstract Hierarchical Reasoning Model (HRM) is a novel approach using two small neural networks recursing at different frequencies. This biologically inspired method beats Large Language models (LLMs) on
arxiv.org
70억 개가 아닌 700만 개
이것만 보고도 삼성이 뭘하려고 하는 지 추론해볼 수 있다.
개인적인 생각이지만 삼성은 LLMs 크기 제약있는 핸드폰에 넣고 싶은 것이다.
TRM(Tiny Recursive Model)이라는 새로운 모델이 ARC-AGI-1, ARC-AGI-2와 같은
매우 어려운 퍼즐 벤치마크에서 대부분의 거대 언어 모델(LLM)보다 높은 정확도를 달성했다는 점이다.
파마미터 수 0.01%밖에 사용하지 않았는데,
Gemini 2.5 Pro 32K와 같은 거대 모델(각각 37.0%, 4.9%)보다 뛰어난 성능이 뛰어났다.
ARC-AGI-1 : 44.6%
ARC-AGI-2 : 7.8%
확인한 예시 : 스도쿠-익스트림
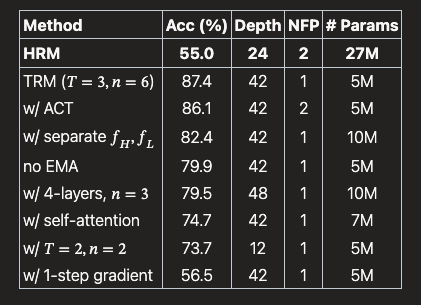
TRM 프레임워크 내에서 두 개의 분리된 신경망 : 정확도 82.4%
단일 신경망 : 정확도 87.4% 상승
추가로 공부
| HRM (Hierarchical Reasoning Model) | 일반 LLM (Transformer 기반) | |
| 아키텍처 | 계층적·순환 구조 — 고수준 플래너와 저수준 실행기 간의 반복적 상호작용 | 대개 트랜스포머 블록(자기어텐션) 기반의 단일-스텝 처리 |
| 파라미터/데이터 효율성 | 소수 파라미터로도 특정 추론 문제에서 높은 효율을 보일 가능성(연구 사례 기반) | 보통 대규모 파라미터와 대량 데이터 필요 — 프리트레인 후 재활용 우수 |
| 추론 스타일 | 반복적·단계적 추론에 강함(계획 → 실행 → 재평가 루프) | 문맥 기반 생성/이해에 강함. 복잡한 계획은 CoT나 외부 플래너와 결합 |
| 응용에 적합한 영역 | 로보틱스, 미로/퍼즐, 최적화·계획 문제 등 순차적 의사결정 | 대화형 AI, 요약, 번역, 코드 생성, 검색-응답 등 광범위한 언어 태스크 |
| 지연/비용 | 작은 모델로 저비용·저지연 목표 가능(구현에 따라 다름) | 대형 모델은 높은 추론비용·지연, 토큰 길이에 따른 비용 증가 |
| 성숙도와 생태계 | 신흥 기술 — 벤치마크·생태계·검증이 아직 발전 중 | 광범위한 라이브러리·툴·사례·상업적 서비스가 이미 성숙 |
| 주요 위험/한계 | 초기 연구 단계로 일반화 가능성·재현성 평가 필요 | hallucination, 비용, 규모·공정성 문제 등 존재 |
HRM의 이해
일반 LLM은 모든 정보를 한 덩어리로HRM은 2개의 층으로 구분
저수준 : 즉각적인 반응, 세부 동작을 담당
고수준 : 정자적 목표, 전략, 맥락 유지
HRM의 개층은 서로 상호작용한다.
High-level RNN ←──────────→ Low-level RNN
↑ ↓
계획(Planning) 세부 행동(Execution)
고수준이 목표를 주면, 저수준이 구체적 실행을 담당
| 1번 | 고수준 RNN | “문을 열라”라는 목표 생성 | 장기 목표를 설정 (door_open = True) |
| 2번 | 저수준 RNN | “손잡이까지 이동 → 손잡이 잡기 → 회전” 수행 | 센서 피드백 기반 세밀 제어 |
| 3번 | 고수준 RNN | 저수준 결과 피드백 수신 | 다음 단계 결정 (“문을 통과하라”) |
결론 :
꼭 큰 모델이 좋은 것만은 아니다. 즉 셀프 어텐션 메커니즘을 좋은 것은 아니다.
한계 :
결론에서 어텐션 메커니즘의 경우는 콘텍스트 윈도우가 길지 않기 때문이라는 것 즉, 콘텍스트가 길어지면 셀프 어텐션이 더 좋다.
'AI' 카테고리의 다른 글
| [ ML/LLM ] 스케일링은 넘어 그것을 향해 (Feat.일리야 수츠케버) (1) | 2025.12.08 |
|---|---|
| [ AI/GPU ] AI의 현재 판도는 GPU,GPU (Feat. 구글 TPU) (0) | 2025.11.29 |
| [ AI/MCP ] REFRAG: RAG (0) | 2025.10.16 |
| [ AI/DeepSeek-R1 ] AI가 스스로 생각하는 법을 배웠다고? (0) | 2025.09.19 |
| [ AI/anthropic-4 ]모델이 계산을 이해하는 방식 (feat. Claude 3.5 Haiku) (5) | 2025.07.27 |



